




安西先生……!!もっと高度なAI画像を生成したいです………
前回の記事に引き続き、今度はチェックポイントやLoRAを利用した画像生成にチャレンジしたいと思います。
前回の記事はこちら↓

細かい解説はなしに、ダウンロード~画像生成までを一気に紹介していきます
チェックポイントによる画風の指定、LoRAによる微調整、ControlNetによるポーズや輪郭の指定で、より高品質で希望に沿った画像生成が可能になります。
併せて、プロンプト/ネガティブプロンプトの指定をしっかり行いましょう。
商用利用する場合は、ダウンロードページでライセンスを確認!

目次
用語
チェックポイント
チェックポイントとは、画像生成AI「Stable Diffusion」の学習過程で作成された画像の特徴を保存した学習モデルファイルのことです。
例えば油絵風で出力したいときは、油絵風のチェックポイントを指定する…といったイメージです。
他にもアニメ風、写実風など、様々なチェックポイントがあります
LoRA
LoRA(Low-Rank Adaptation)とは、既存のモデルに追加学習を行うことでより精度を高め、理想の画像を生成するための仕組みです。
1つのチェックポイントに対して、複数のLoRAを適用可能です。
パトレイバーに例えると、イングラムの学習データ的なものでしょうか
野明が操縦する1号機は手先が器用なLoRAで、太田さんが操縦する2号機は射撃が得意なLoRA…みたいな
ControlNet
ControlNetとは、視覚的な条件を参考画像から抽出して、生成する画像に反映する拡張機能です。
ポーズ、輪郭、解像度、色調などをコントロールし、より正確な画像生成を実現します。
2023年初頭に発表されました。
プロンプト(テキスト)で画像を生成するのではなく、画像から画像を生成する…画像生成の進化系です
ダウンロード
チェックポイントとLoRAのダウンロード先としては、「Civitai」または「Hugging Face」が主流です。
今回は「Civitai」での手順を紹介します。
まずは「Civitai」に移動します。
●チェックポイント
検索窓に「CounterfeitXL」と入力し、結果をクリックします。
こちらはアニメ系のチェックポイントになります。
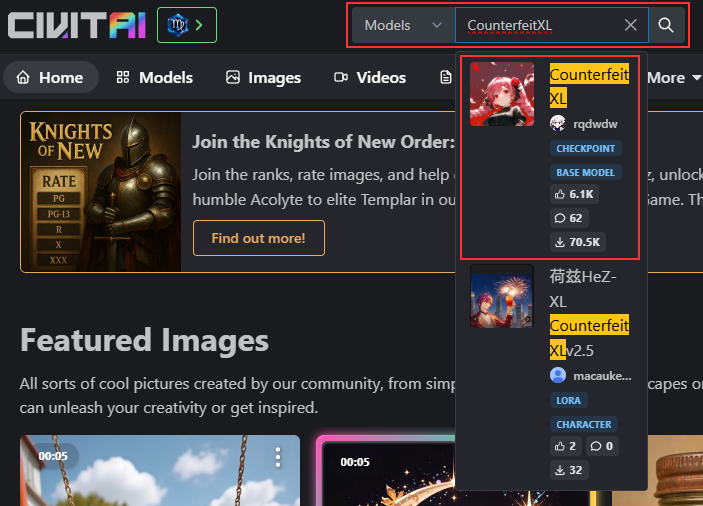
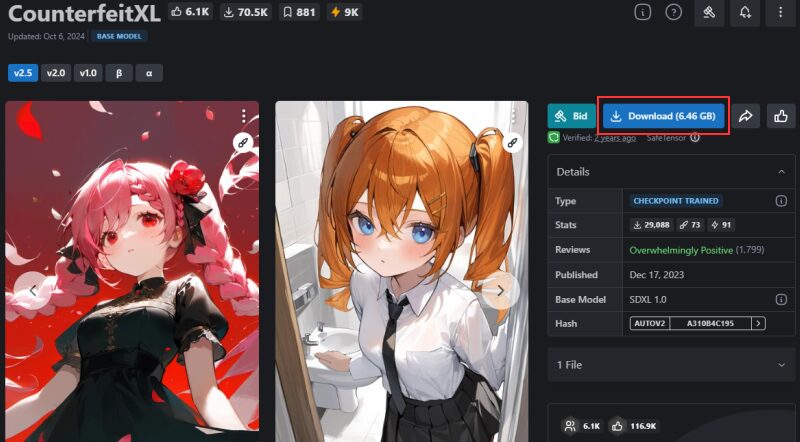
「Download」をクリックし、チェックポイントをダウンロードします。
(ファイル名:counterfeitxl_v25.safetensors)
●LoRA
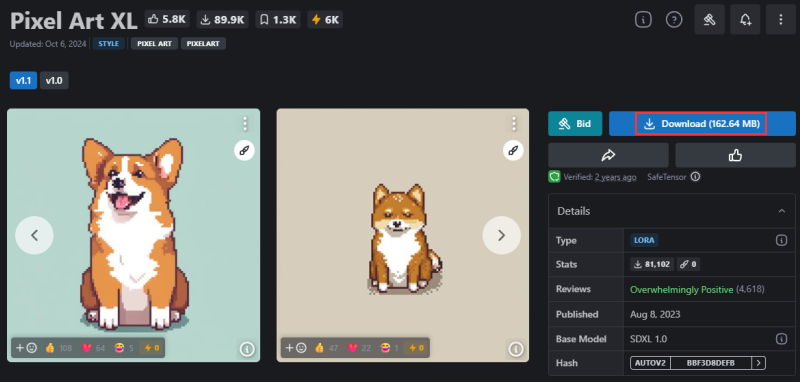
検索窓に「Pixel Art XL」と入力し、結果をクリックします。
適用するとピクセルアートなスタイルになるLoRAです。
「Download」をクリックし、LoRAをダウンロードします。
(ファイル名:pixel-art-xl-v1.1.safetensors)
●ControlNet
ダウンロード不要。
後ほど「設定」で紹介する「URLからインストール」によりインストール可能です。
以上でダウンロードは完了です。
チェックポイントには、SDやSDXLなどのベースモデルがあります。
LoRA、ControlNetを利用する場合、基本的にはこのベースモデルと合わせたものを用意する必要があります。(互換性の問題)
例えば「CounterfeitXL」でLoRAを使いたい場合は、SDXL1.0用のLoRAを用意します。
アップロード
●チェックポイント
ConoHa AI Canvasにログインし、「詳細情報」の「ファイルマネージャー」をクリックします。
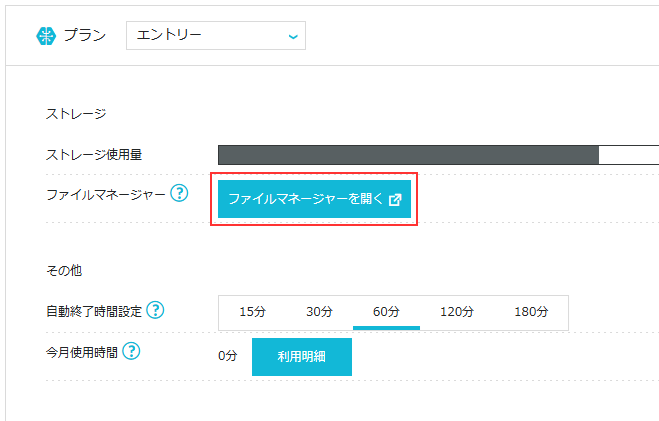
先ほどダウンロードしたチェックポイントを「home > data > models > Stable-diffusion」にアップロードします。
●LoRA
先ほどダウンロードしたLoRAを「home > data > models > Lora」にアップロードします。
●ControlNet
アップロード不要。
後ほど「設定」で紹介する「URLからインストール」によりインストール可能です。
以上でアップロードは完了です。
設定
WebUIを起動します。
チェックポイント → LoRA → ControlNet の順に設定していきます。
チェックポイント
「Stable Diffusionのcheckpoint」の▼をクリックし、「counterfeitxl_v25.safetensors」を選択します。(確定までにしばらく時間がかかります)

次にプロンプトを入力します。
ここで、高品質な画像生成をするためのキーワードをいくつか紹介します。
先ほどダウンロードした「CounterfeitXL」のページでも、「Generation data」という項目にプロンプトとネガティブプロンプトが公開されています。(参考画像をクリックすると表示されます)
参考画像に近づけたい方は、そのままコピペしてみましょう。
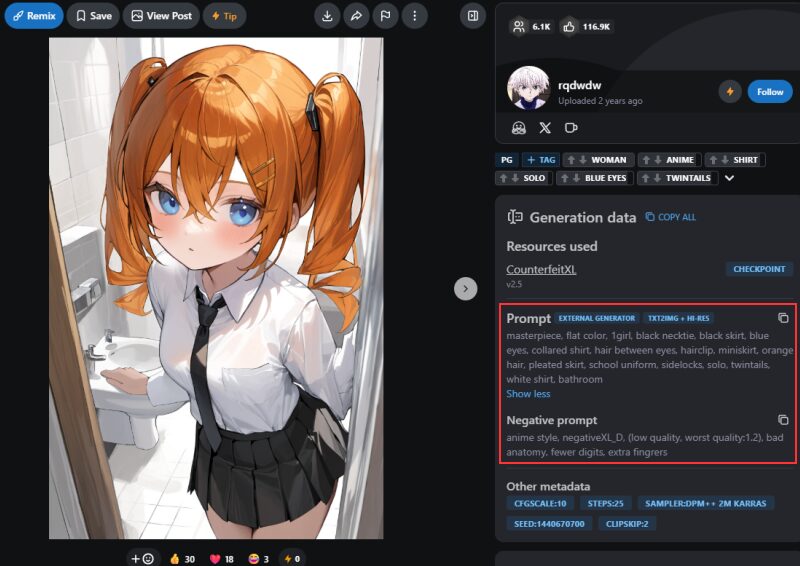
今回は以下のプロンプトで画像生成してみます。
プロンプト:
quality 8K, UnrealEngine, masterpiece, best quality, whole body, mandarin orange, beautiful girl, hat, China, green eyes, hand on hip
ネガティブプロンプト:
anime style, negativeXL_D, (low quality, worst quality:1.2), bad anatomy, fewer digits, extra fingrers, low quality, worst quality, blurry, bad fingers, extra fingers, liquid fingers, fused fingers, bad hands, poorly drawn hands
ちなみに、whole body(全身)にすると、顔が崩れてしまう傾向があります。
顔は複雑なパーツのため、低い解像度だと表現するのが難しいようです…(;´Д`)
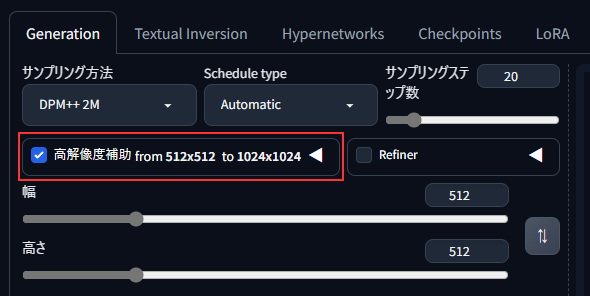
「高解像度補助」にチェックすることで、かなり改善しました。
生成結果は以下のようになりました。

モデルの画風が反映されているのが分かります。
LoRA
「LoRA」タブ → 「pixel-art-xl-v1.1」をクリックすると、プロンプトに<lora:pixelbuildings128-v2:1>と自動入力されます。
この状態で生成を実行すると、ピクセルアートスタイルになりました。

ControlNet
ControlNetを利用するためには、WebUIへのインストールが必要です。
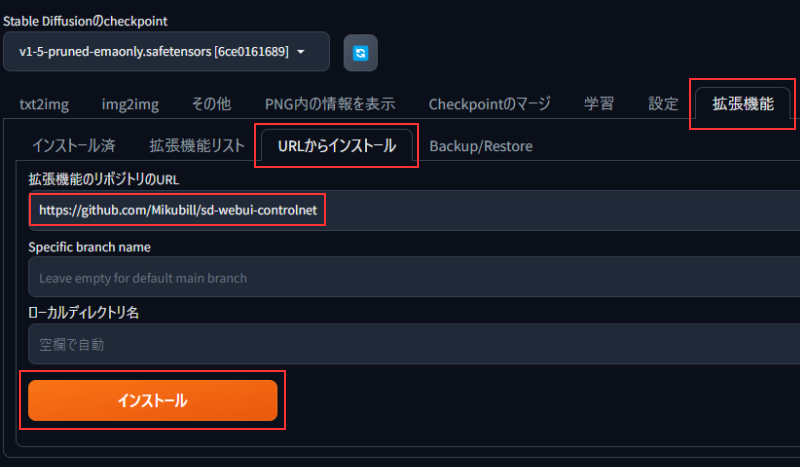
「拡張機能」タブ → 「URLからインストール」タブをクリックします。
次に「拡張機能のリポジトリのURL」に以下のURLを記入し、インストールボタンをクリックします。
<URL>
https://github.com/Mikubill/sd-webui-controlnet
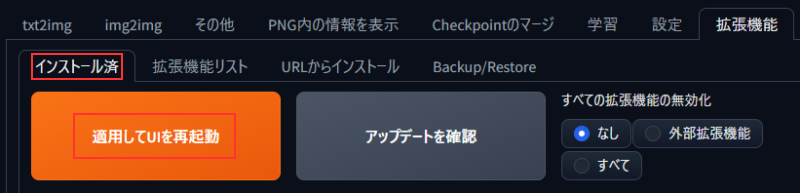
インストールが完了したら、「インストール済」タブの「適用してUIを再起動」をクリックします。
WebUIの再起動後、ControlNetの表示がされていればインストール完了です。
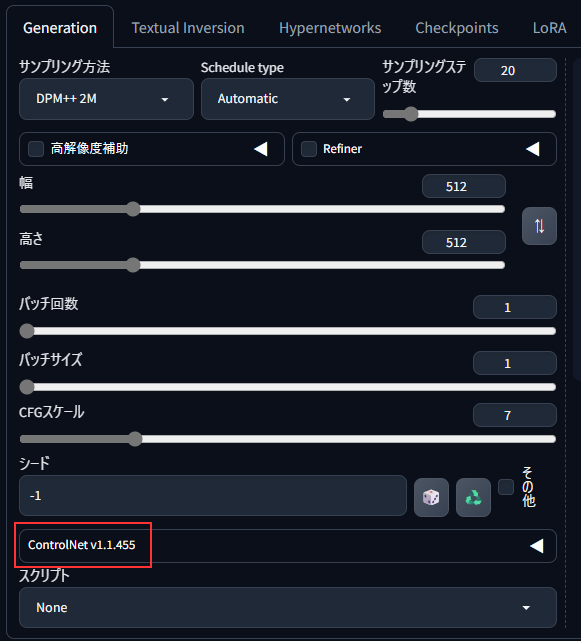
今回は「OpenPose」というポーズ抽出用のControlNetを使用します。
- ControlNetの◀部分をクリックして画面を開く
- ポーズ抽出したい画像をドロップ
- 「有効化」 → チェックを入れる
- 「Control Type」 → 「OpenPose」
- 「プリプロセッサ」 → 「openpose_full」
- 「モデル」 → 「control_v11p_sd15_openpose [cab727d4]」(もし表示されなければ横の更新ボタンを押す)
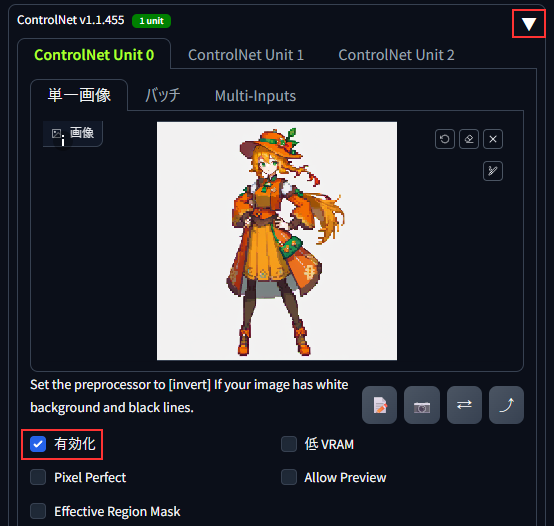
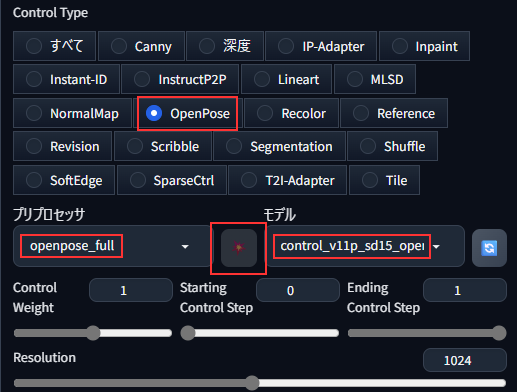
上記を全て確認したら、プロセッサ実行ボタン(爆発マーク)を押します。
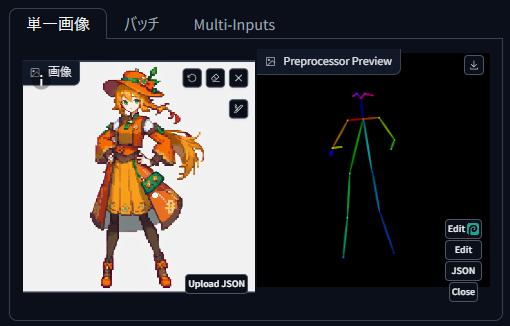
「Preprocessor Preview」にレインボーな棒人間が出力されました。
この棒人間と同じポーズで、画像を生成することが可能になります。
あとはいつものようにプロンプトに入力して、画像生成を実行します。
生成結果は以下のようになりました。

棒人間と同じポーズになっています。
さらに、プロンプトを少し変更して生成してみました。

この棒人間はダウンロードして再利用したり、「OpenPose Editor」という拡張機能によって編集も可能です。
余談:
「AI Canvas」では、ControlNetがSD1.5用しかインストールされないため、チェックポイントをSDXL1.0の「counterfeitxl_v25」から、SD1.5の「Dark Sushi Mix 2.25D」に変更して、OpenPoseが適用されるようにしました。
商用利用
画像生成AI「Stable Diffusion」は、生成した画像についての権利を主張しないとしています。
また、以下の場合を除き商用利用が可能とされています。
- 商用利用不可のチェックポイントを使用した場合
- 商用利用不可のチェックポイントをLoRAで学習させた場合
- 商用利用不可の画像を読み込んだ場合
通常はテキストによる「txt2img」で指定しますが、既存画像による「img2img」で指定する方法もあります。
商用利用不可のチェックポイントの確認方法ですが、ダウンロードページに「CreativeML Open RAIL-M」か、「CreativeML Open RAIL++-M」と表示されていれば、とりあえず安心とのことです。

まとめ
前回より高度な画像生成ができました!
前回は見えなかった「画像生成沼」が目の前に現れてきて、理想の画像を生成するためには壁が高く、まだまだ勉強が必要だな…と感じました。
ChatGPT等のお手軽な画像生成と上手に使い分けできると良いですね


コメント